Make your PDFs searchable using OCR for free on macOS
Ever encountered a PDF from a scanned document where Ctrl+F does not work? No text selection too?
What you need is to use OCR to make a PDF searchable! There are many paid options for the Mac, but if you are willing to use the command line… you can get some quite good and fast results using parallel processing.
All for free!
Requirements and basic usage
First, install Homebrew and then install ocrmypdf.
1
brew install ocrmypdf
Usage example:
1
ocrmypdf input.pdf output.pdf
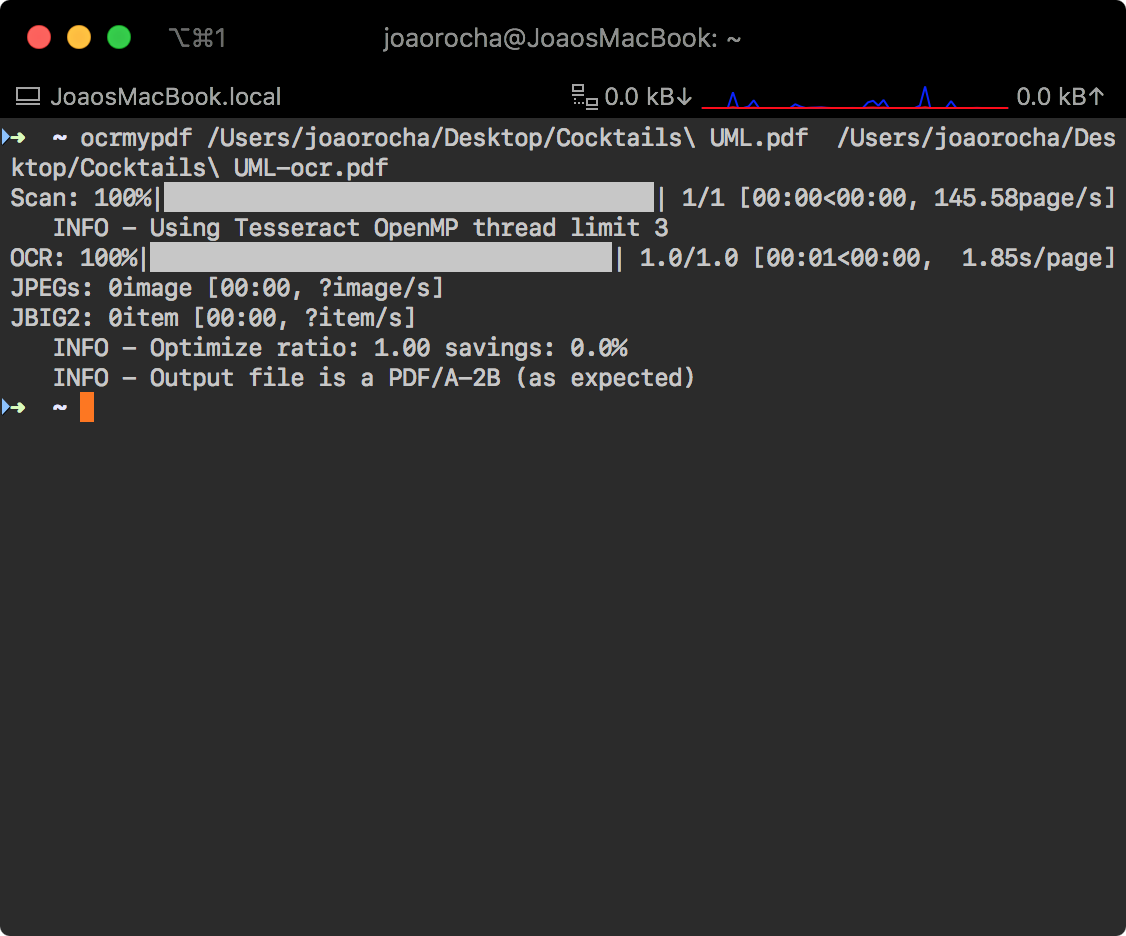
This was tested in macOS Catalina (10.15.4).
Advanced: handling encrypted PDFs + Deep Search
Sometimes the PDFs will be encrypted, and ocrmypdf will complain after the fact. In those cases, you can run these command to decrypt and then apply OCR to all PDFs in the current directory.
- These commands will also perform OCR on all PDFs within the current folder and its subfolders, i.e. with deep search:
1
2
3
4
5
6
7
8
9
# to delete any existing OCR'd files and redo run (if there are already semi-processed files due to errors, for example)
# -print0 + -0 in xargs -> handle files with spaces
find . -name "*-decrypted.pdf" -print0 | xargs -0 -I{} rm -f {};
find . -name "*-ocr.pdf" -print0 | xargs -0 -I{} rm -f {};
# apply OCR in parallel (all available cores will be used - Command valid only for macos, for Linux replace sysctl -n hw.logicalcpu with nproc)
find . -name "*.pdf" -print0 | xargs -0 -P $(sysctl -n hw.logicalcpu) -n 1 -I{} qpdf --decrypt {} {}-decrypted.pdf;
find . -name "*-decrypted.pdf" -print0 | xargs -0 -P $(sysctl -n hw.logicalcpu) -n 1 -I{} ocrmypdf {} {}-ocr.pdf;
# remove intermediate files (decrypted pdfs)
find . -name "*-decrypted.pdf" -print0 | xargs -0 -I{} rm -f {};
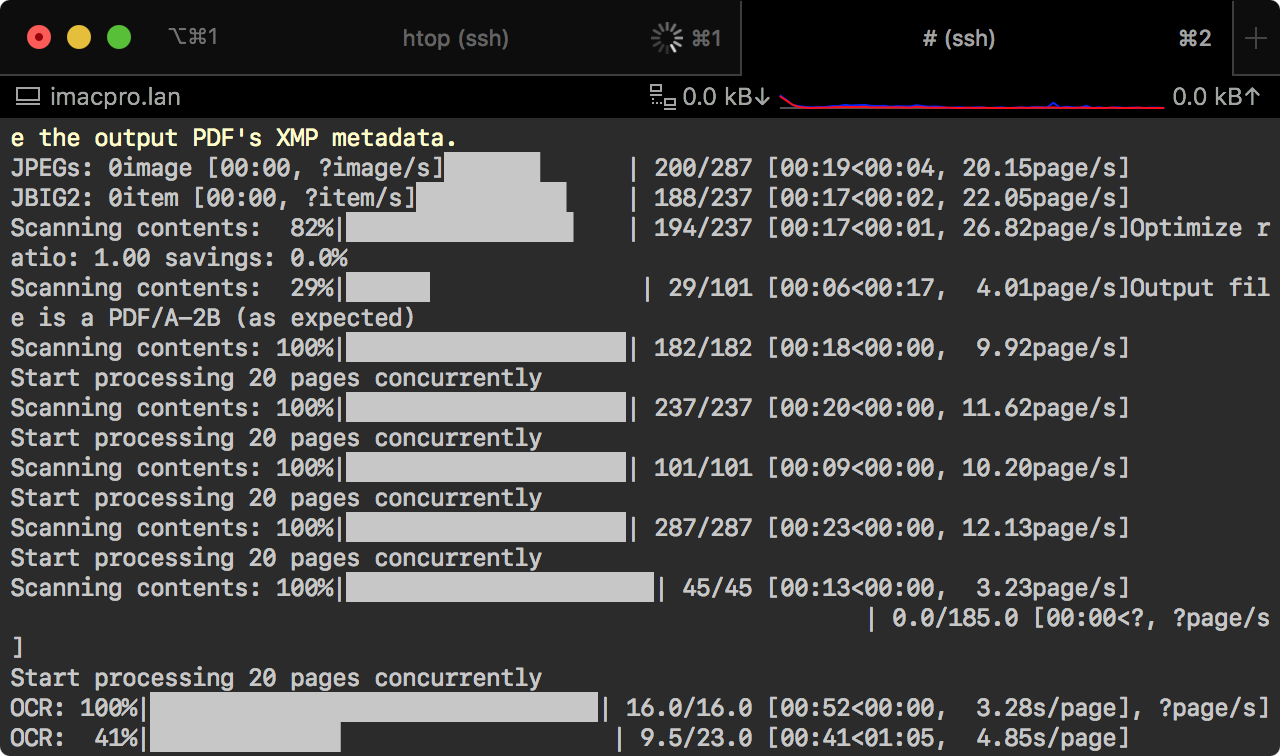
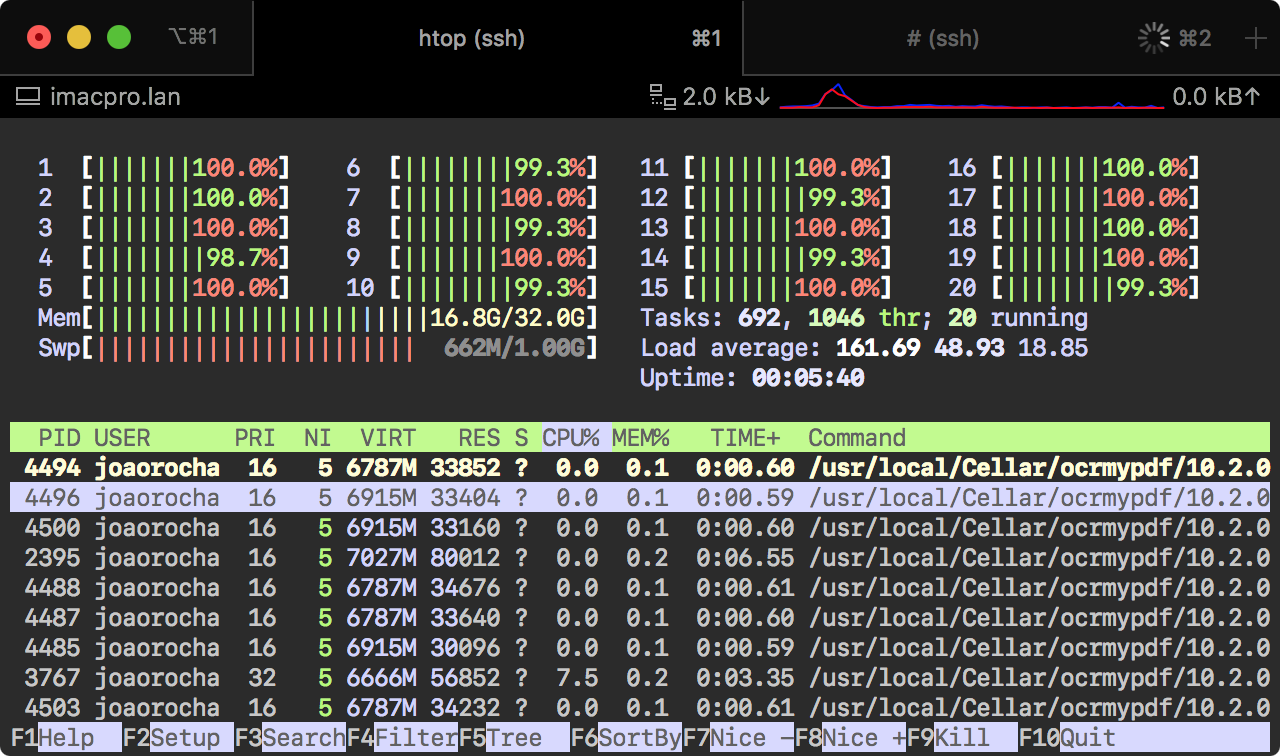
If everything goes as planned, you will have parallel processing of OCR for your PDFs:
End result
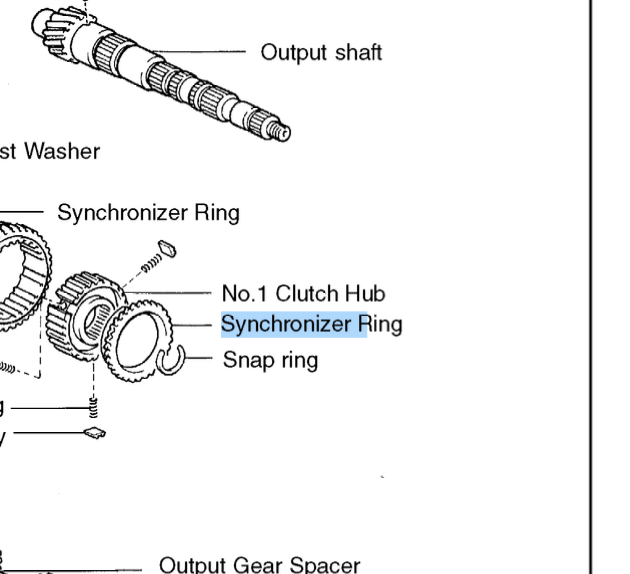
And you will have proper text selection and search, even in images with captions:
Tell me how it goes for you!